Extended examples
Authors: Alan Murphy, Brian Schilder, and Nathan Skene
Authors: Alan Murphy, Brian Schilder, and Nathan Skene
Updated: Mar-20-2026
Source: Updated: Mar-20-2026
vignettes/extended.Rmd
extended.RmdSetup
## Loading required package: RNOmni## Registered S3 method overwritten by 'bit64':
## method from
## print.bitstring toolsNOTE: This documentation is for the development
version of EWCE. See Bioconductor
for documentation on the current release version.
Run cell-type enrichment tests
Introduction
In the following vignette, we provide more a more in-depth version of the examples provided in the Getting started vignette.
Prepare input data
CellTypeDataset
For this example we use a subset of the genes from the merged dataset
generated in the Create a
CellTypeDataset section below, which is accessed using
ewceData::ctd().
CTD levels
Each level of a CTD corresponds to increasingly refined
cell-type/-subtype annotations. For example, in the CTD
ewceData::ctd() level 1 includes the cell-type
“interneurons”, while level 2 breaks these this group into 16 different
interneuron subtypes (“Int…”).
## Load merged cortex and hypothalamus dataset generated by Karolinska institute
ctd <- ewceData::ctd() # i.e. ctd_MergedKI## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache
try({
plt <- EWCE::plot_ctd(ctd = ctd,
level = 1,
genes = c("Apoe","Gfap","Gapdh"),
metric = "mean_exp")
})
Note - You can load ewceData::ctd()
offline by passing localhub = TRUE. This will work off a
previously cached version of the reference dataset from
ExperimentHub.
Gene lists
For the first demonstration of EWCE we will test for
whether genes that are genetically associated with Alzheimer’s disease
are enriched in any particular cell type.
This example gene list is stored within the ewceData
package:
hits <- ewceData::example_genelist()## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache
print(hits)## [1] "APOE" "BIN1" "CLU" "ABCA7" "CR1" "PICALM"
## [7] "MS4A6A" "CD33" "MS4A4E" "CD2AP" "EOGA1" "INPP5D"
## [13] "MEF2C" "HLA-DRB5" "ZCWPW1" "NME8" "PTK2B" "CELF1"
## [19] "SORL1" "FERMT2" "SLC24A4" "CASS4"Note - You can load
ewceData::example_genelist() offline by passing
localhub = TRUE. This will work off a previously cached
version of the reference dataset from ExperimentHub.
Gene formats and species
All gene IDs are assumed by the package to be provided in gene symbol
format (rather than Ensembl/Entrez). Symbols can be provided as any
species-specific gene symbols supported by the package
orthogene, though the genelistSpecies argument
will need to be set appropriately.
Likewise, the single-cell dataset can be from any species, but the
sctSpecies argument must be set accordingly.
The example gene list here stores the human genes associated with human disease, and hence are HGNC symbols.
The next step is to determine the most suitable background set. This
can be user-supplied, but by default the background is all 1:1 ortholog
genes shared by genelistSpecies and sctSpecies
that are also present in sct_data.
Notes on orthogene
orthogene substantially improves upon previous ortholog
translations that used the static
ewceData::mouse_to_human_homologs() file as the former is
updated using the Homologene database
periodically.
exp <- ctd[[1]]$mean_exp
#### Old conversion method ####
#if running offline pass localhub = TRUE
m2h <- ewceData::mouse_to_human_homologs()## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache
exp_old <- exp[rownames(exp) %in% m2h$MGI.symbol,]
#### New conversion method (used by EWCE internally) ####
exp_new <- orthogene::convert_orthologs(gene_df = exp,
input_species = "mouse",
output_species = "human",
method = "homologene")## Preparing gene_df.## Dense matrix format detected.## Extracting genes from rownames.## 15,259 genes extracted.## Converting mouse ==> human orthologs using: homologene## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Checking for genes without orthologs in human.## Extracting genes from input_gene.## 13,416 genes extracted.## Extracting genes from ortholog_gene.## 13,416 genes extracted.## Checking for genes without 1:1 orthologs.## Dropping 46 genes that have multiple input_gene per ortholog_gene (many:1).## Dropping 56 genes that have multiple ortholog_gene per input_gene (1:many).## Filtering gene_df with gene_map## Setting ortholog_gene to rownames.##
## =========== REPORT SUMMARY ===========## Total genes dropped after convert_orthologs :
## 2,016 / 15,259 (13%)## Total genes remaining after convert_orthologs :
## 13,243 / 15,259 (87%)
#### Report ####
message("The new method retains ",
formatC(nrow(exp_new) - nrow(exp_old), big.mark = ","),
" more genes than the old method.")## The new method retains 918 more genes than the old method.orthogene is also used internally to standardise gene
lists supplied to EWCE functions, such as
EWCE::bootstrap_enrichment_test(hits = <gene_list>).
Not only can it map these gene lists across species, but it can also map them within species. For example, if you provide a list of Ensembl IDs, it will automatically convert them to standardised HGNC gene symbols so they’re compatible with the similarly standardised CellTypeDataset.
Setting analysis parameters
We now need to set the parameters for the analysis. For a publishable
analysis we would want to generate over 10,000 random lists and
determine their expression levels, but for computational speed let us
only use reps=100. We want to analyse level 1 annotations
so set level to 1.
# Use 100 bootstrap lists for speed, for publishable analysis use >=10000
reps <- 100
# Use level 1 annotations (i.e. Interneurons)
annotLevel <- 1 Enrichment tests
Default tests
We have now loaded the SCT data, prepared the gene lists and set the parameters. We run the model as follows.
Note: We set the seed at the top of this vignette to ensure reproducibility in the bootstrap sampling function.
Parallelisation
You can now speed up the bootstrapping process by parallelising
across multiple cores with the parameter no_cores
(=1 by default).
# Bootstrap significance test, no control for transcript length and GC content
full_results <- EWCE::bootstrap_enrichment_test(sct_data = ctd,
sctSpecies = "mouse",
genelistSpecies = "human",
hits = hits,
reps = reps,
annotLevel = annotLevel)## 1 core(s) assigned as workers (3 reserved).## Generating gene background for mouse x human ==> human## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Using cached file: /github/home/.cache/R/orthogene/all_genes-10090-homologene.csv.gz## Returning all 21,207 genes from mouse.## --
## --## Preparing gene_df.## data.table format detected.## Extracting genes from Gene.Symbol.## 21,207 genes extracted.## Converting mouse ==> human orthologs using: homologene## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Checking for genes without orthologs in human.## Extracting genes from input_gene.## 17,355 genes extracted.## Extracting genes from ortholog_gene.## 17,355 genes extracted.## Checking for genes without 1:1 orthologs.## Dropping 131 genes that have multiple input_gene per ortholog_gene (many:1).## Dropping 498 genes that have multiple ortholog_gene per input_gene (1:many).## Filtering gene_df with gene_map## Adding input_gene col to gene_df.## Adding ortholog_gene col to gene_df.##
## =========== REPORT SUMMARY ===========## Total genes dropped after convert_orthologs :
## 4,725 / 21,207 (22%)## Total genes remaining after convert_orthologs :
## 16,482 / 21,207 (78%)## --##
## =========== REPORT SUMMARY ===========## 16,482 / 21,207 (77.72%) target_species genes remain after ortholog conversion.## 16,482 / 19,129 (86.16%) reference_species genes remain after ortholog conversion.## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## --##
## =========== REPORT SUMMARY ===========## 19,129 / 19,129 (100%) target_species genes remain after ortholog conversion.## 19,129 / 19,129 (100%) reference_species genes remain after ortholog conversion.## 16,482 intersect background genes used.## Standardising CellTypeDataset## Checking gene list inputs.## Running without gene size control.## 17 hit gene(s) remain after filtering.## Computing gene scores.## Using previously sampled genes.## Computing gene counts.## Testing for enrichment in 7 cell types...## Sorting results by p-value.## Computing BH-corrected q-values.## 1 significant cell type enrichment results @ q<0.05 :## CellType annotLevel p fold_change sd_from_mean q
## 1 microglia 1 0 1.965915 3.938119 0Note - You can run
bootstrap_enrichment_test() offline by passing
localhub = TRUE. This will work off a previously cached
version of the reference dataset from ExperimentHub.
A note on both the background and target gene lists, other common
gene list objects can be used as inputs such as
BiocSet::BiocSet and GSEABase::GeneSet. Below
is an example of how to format each for the target gene list
(hits):
if(!"BiocSet" %in% rownames(installed.packages())) {
BiocManager::install("BiocSet")
}
if(!"GSEABase" %in% rownames(installed.packages())) {
BiocManager::install("GSEABase")
}
library(BiocSet)
library(GSEABase)
# Save both approaches as hits which will be passed to bootstrap_enrichment_test
genes <- c("Apoe","Inpp5d","Cd2ap","Nme8",
"Cass4","Mef2c","Zcwpw1","Bin1",
"Clu","Celf1","Abca7","Slc24a4",
"Ptk2b","Picalm","Fermt2","Sorl1")
#BiocSet::BiocSet, BiocSet_target contains the gene list target
BiocSet_target <- BiocSet::BiocSet(set1 = genes)
hits <- unlist(BiocSet::es_element(BiocSet_target))
#GSEABase::GeneSet, GeneSet_target contains the gene list target
GeneSet_target <- GSEABase::GeneSet(genes)
hits <- GSEABase::geneIds(GeneSet_target) The main table of results is stored in
full_results$results. We can see the most significant
results using:
knitr::kable(full_results$results)| CellType | annotLevel | p | fold_change | sd_from_mean | q | |
|---|---|---|---|---|---|---|
| microglia | microglia | 1 | 0.00 | 1.9659148 | 3.9381188 | 0.000 |
| astrocytes_ependymal | astrocytes_ependymal | 1 | 0.13 | 1.2624889 | 1.1553910 | 0.455 |
| pyramidal_SS | pyramidal_SS | 1 | 0.80 | 0.8699242 | -0.8226268 | 1.000 |
| oligodendrocytes | oligodendrocytes | 1 | 0.87 | 0.7631149 | -1.0861761 | 1.000 |
| pyramidal_CA1 | pyramidal_CA1 | 1 | 0.89 | 0.8202496 | -1.1738063 | 1.000 |
| endothelial_mural | endothelial_mural | 1 | 0.90 | 0.7674534 | -1.1811797 | 1.000 |
| interneurons | interneurons | 1 | 1.00 | 0.4012954 | -3.4703413 | 1.000 |
Plot results
The results can be visualised using another function, which shows for each cell type, the number of standard deviations from the mean the level of expression was found to be in the target gene list, relative to the bootstrapped mean:
try({
plot_list <- EWCE::ewce_plot(total_res = full_results$results,
mtc_method ="BH",
ctd = ctd)
# print(plot_list$plain)
})For publications it can be useful to plot a dendrogram alongside the plot. This can be done by including the cell type data as an additional argument. The dendrogram should automatically align with the graph ticks (thanks to Robert Gordon-Smith for this solution):
print(plot_list$withDendro) If you want to view the characteristics of enrichment for each gene
within the list then the generate_bootstrap_plots function
should be used. This saves the plots into the BootstrapPlots folder.
This takes the results of a bootstrapping analysis so as to only
generate plots for significant enrichments. The
listFileName argument is used to give the generated graphs
a particular file name. The savePath argument is used here
to save the files to a temporary directory, this can be updated to your
preferred location. The file path where it was saved is returned so the
temporary directory can be located if used.
bt_plot_location <- EWCE::generate_bootstrap_plots(
sct_data = ctd,
hits = hits,
sctSpecies = "mouse",
genelistSpecies = "human",
reps = reps,
annotLevel = annotLevel,
full_results = full_results)Control for transcript length and GC-content
When analysing genes found through genetic association studies it is important to consider biases which might be introduced as a result of transcript length and GC-content. The package can control for these by selecting the bootstrap lists such that the ith gene in the random list has properties similar to theith gene in the target list. To enable the algorithm to do this it needs to be passed the gene lists as HGNC symbols rather than MGI.
The bootstrapping function then takes different arguments:
# Bootstrap significance test controlling for transcript length and GC content
#if running offline pass localhub = TRUE
cont_results <- EWCE::bootstrap_enrichment_test(
sct_data = ctd,
hits = hits,
sctSpecies = "mouse",
genelistSpecies = "human",
reps = reps,
annotLevel = annotLevel,
geneSizeControl = TRUE)## 1 core(s) assigned as workers (3 reserved).## Generating gene background for mouse x human ==> human## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Using cached file: /github/home/.cache/R/orthogene/all_genes-10090-homologene.csv.gz## Returning all 21,207 genes from mouse.## --
## --## Preparing gene_df.## data.table format detected.## Extracting genes from Gene.Symbol.## 21,207 genes extracted.## Converting mouse ==> human orthologs using: homologene## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Checking for genes without orthologs in human.## Extracting genes from input_gene.## 17,355 genes extracted.## Extracting genes from ortholog_gene.## 17,355 genes extracted.## Checking for genes without 1:1 orthologs.## Dropping 131 genes that have multiple input_gene per ortholog_gene (many:1).## Dropping 498 genes that have multiple ortholog_gene per input_gene (1:many).## Filtering gene_df with gene_map## Adding input_gene col to gene_df.## Adding ortholog_gene col to gene_df.##
## =========== REPORT SUMMARY ===========## Total genes dropped after convert_orthologs :
## 4,725 / 21,207 (22%)## Total genes remaining after convert_orthologs :
## 16,482 / 21,207 (78%)## --##
## =========== REPORT SUMMARY ===========## 16,482 / 21,207 (77.72%) target_species genes remain after ortholog conversion.## 16,482 / 19,129 (86.16%) reference_species genes remain after ortholog conversion.## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## --##
## =========== REPORT SUMMARY ===========## 19,129 / 19,129 (100%) target_species genes remain after ortholog conversion.## 19,129 / 19,129 (100%) reference_species genes remain after ortholog conversion.## 16,482 intersect background genes used.## Standardising CellTypeDataset## Checking gene list inputs.## Running with gene size control.## Warning: sctSpecies_origin not provided. Setting to 'mouse' by default.## Retrieving all genes using: gprofiler## Retrieving all organisms available in gprofiler.## Using stored `gprofiler_orgs`.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: hsapiens## Using cached file: /github/home/.cache/R/orthogene/all_genes-hsapiens-gprofiler.csv.gz## Returning all 78,687 genes from human.## 78,687 human Ensembl IDs and 41,081 human Gene Symbols imported.## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache## Controlled bootstrapping network generated.## 17 hit gene(s) remain after filtering.## Computing gene scores.## Using previously sampled genes.## Computing gene counts.## Testing for enrichment in 7 cell types...## Sorting results by p-value.## Computing BH-corrected q-values.## 1 significant cell type enrichment results @ q<0.05 :## CellType annotLevel p fold_change sd_from_mean q
## 1 microglia 1 0 1.986637 3.566007 0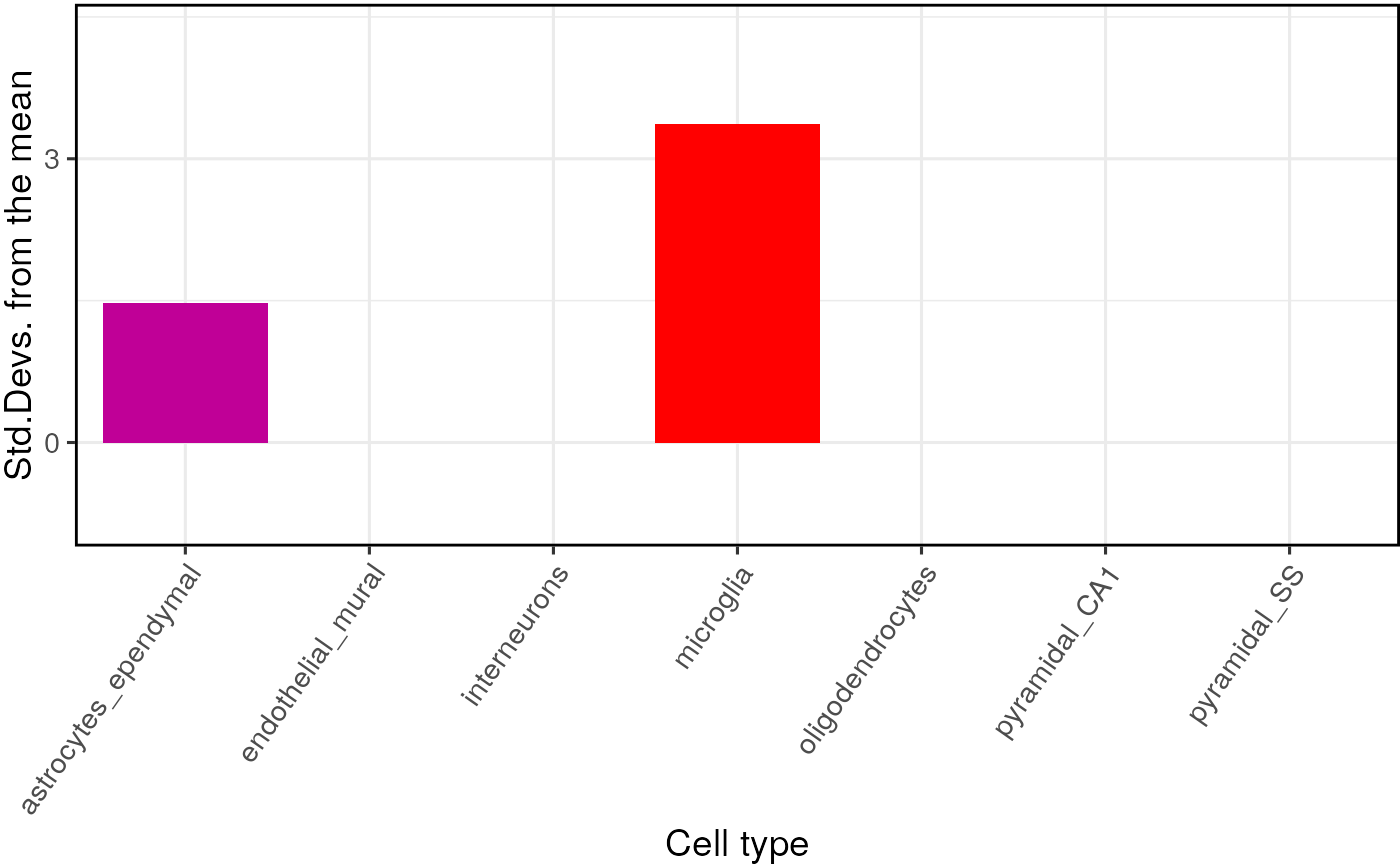
Test different CTD levels
Both the analyses shown above were run on level 1 annotations. It is possible to test on the level 2 cell type level annotations by changing one of the arguments.
# Bootstrap significance test controlling for transcript length and GC content
#if running offline pass localhub = TRUE
cont_results <- EWCE::bootstrap_enrichment_test(sct_data = ctd,
hits = hits,
sctSpecies = "mouse",
genelistSpecies = "human",
reps = reps,
annotLevel = 2,
geneSizeControl = TRUE)## 1 core(s) assigned as workers (3 reserved).## Generating gene background for mouse x human ==> human## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Using cached file: /github/home/.cache/R/orthogene/all_genes-10090-homologene.csv.gz## Returning all 21,207 genes from mouse.## --
## --## Preparing gene_df.## data.table format detected.## Extracting genes from Gene.Symbol.## 21,207 genes extracted.## Converting mouse ==> human orthologs using: homologene## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Checking for genes without orthologs in human.## Extracting genes from input_gene.## 17,355 genes extracted.## Extracting genes from ortholog_gene.## 17,355 genes extracted.## Checking for genes without 1:1 orthologs.## Dropping 131 genes that have multiple input_gene per ortholog_gene (many:1).## Dropping 498 genes that have multiple ortholog_gene per input_gene (1:many).## Filtering gene_df with gene_map## Adding input_gene col to gene_df.## Adding ortholog_gene col to gene_df.##
## =========== REPORT SUMMARY ===========## Total genes dropped after convert_orthologs :
## 4,725 / 21,207 (22%)## Total genes remaining after convert_orthologs :
## 16,482 / 21,207 (78%)## --##
## =========== REPORT SUMMARY ===========## 16,482 / 21,207 (77.72%) target_species genes remain after ortholog conversion.## 16,482 / 19,129 (86.16%) reference_species genes remain after ortholog conversion.## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## --##
## =========== REPORT SUMMARY ===========## 19,129 / 19,129 (100%) target_species genes remain after ortholog conversion.## 19,129 / 19,129 (100%) reference_species genes remain after ortholog conversion.## 16,482 intersect background genes used.## Standardising CellTypeDataset## Checking gene list inputs.## Running with gene size control.## Warning: sctSpecies_origin not provided. Setting to 'mouse' by default.## Retrieving all genes using: gprofiler## Retrieving all organisms available in gprofiler.## Using stored `gprofiler_orgs`.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: hsapiens## Using cached file: /github/home/.cache/R/orthogene/all_genes-hsapiens-gprofiler.csv.gz## Returning all 78,687 genes from human.## 78,687 human Ensembl IDs and 41,081 human Gene Symbols imported.## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache## Controlled bootstrapping network generated.## 17 hit gene(s) remain after filtering.## Computing gene scores.## Using previously sampled genes.## Computing gene counts.## Testing for enrichment in 48 cell types...## Sorting results by p-value.## Computing BH-corrected q-values.## 0 significant cell type enrichment results @ q<0.05 :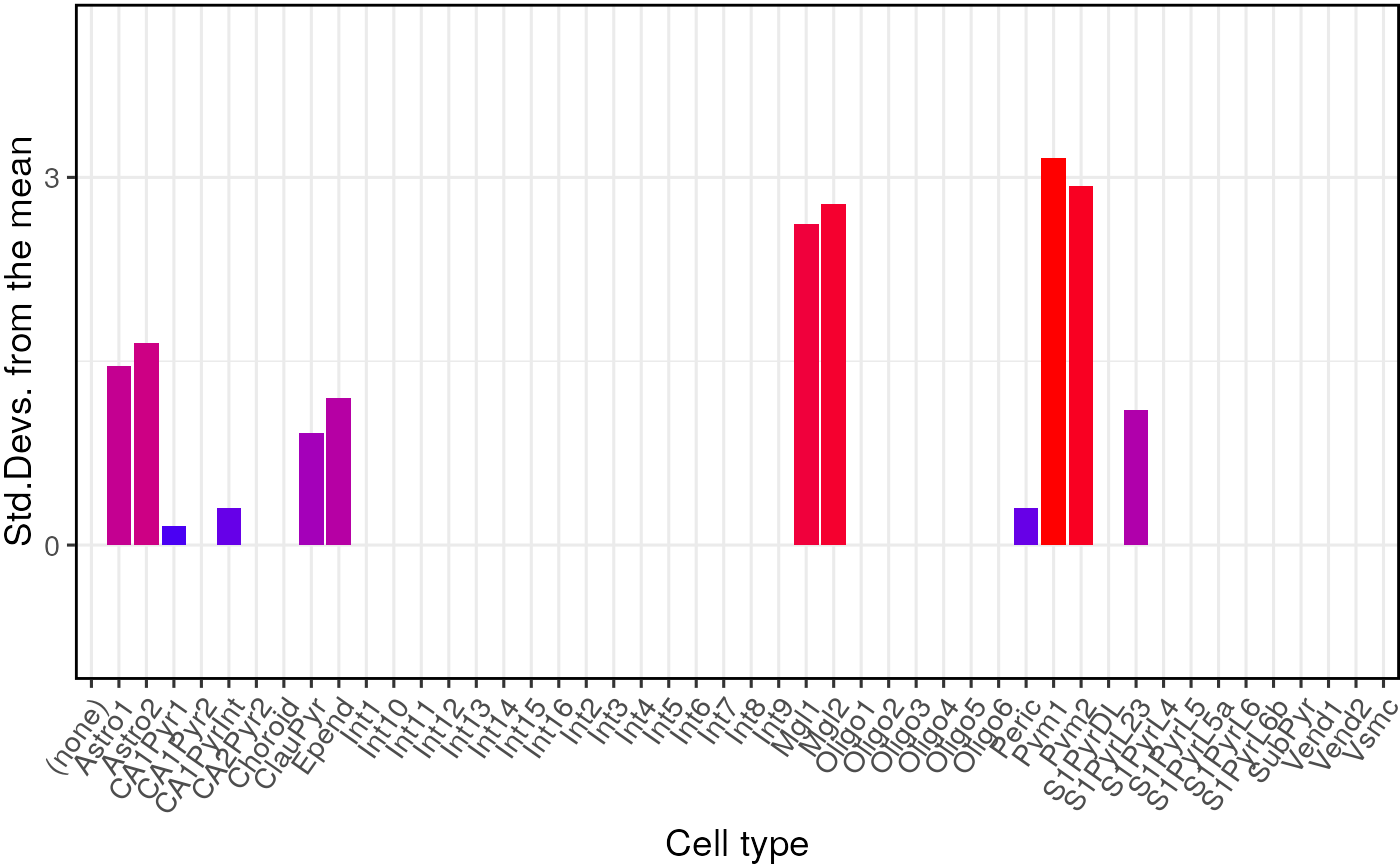
Plot results from multiple sets of enrichment results
It is often useful to plot results from multiple gene list analyses
together. The ewce_plot function allows multiple enrichment
analyses to be performed together. To achieve this the results data
frames are just appended onto each other, with an additional
list column added detailing which analysis they relate
to.
To demonstrate this we need to first generate a second analysis so let us sample thirty random genes, and run the bootstrapping analysis on it.
#### Generate random gene list ####
#if running offline pass localhub = TRUE
human.bg <- ewceData::mouse_to_human_homologs()$HGNC.symbol## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache
gene.list.2 <- sample(human.bg,size = 30)
#if running offline pass localhub = TRUE
second_results <- EWCE::bootstrap_enrichment_test(sct_data = ctd,
sctSpecies = "mouse",
hits = gene.list.2,
reps = reps,
annotLevel = 1)## 1 core(s) assigned as workers (3 reserved).## Warning: genelistSpecies not provided. Setting to 'human' by default.## Generating gene background for mouse x human ==> human## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Using cached file: /github/home/.cache/R/orthogene/all_genes-10090-homologene.csv.gz## Returning all 21,207 genes from mouse.## --
## --## Preparing gene_df.## data.table format detected.## Extracting genes from Gene.Symbol.## 21,207 genes extracted.## Converting mouse ==> human orthologs using: homologene## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Checking for genes without orthologs in human.## Extracting genes from input_gene.## 17,355 genes extracted.## Extracting genes from ortholog_gene.## 17,355 genes extracted.## Checking for genes without 1:1 orthologs.## Dropping 131 genes that have multiple input_gene per ortholog_gene (many:1).## Dropping 498 genes that have multiple ortholog_gene per input_gene (1:many).## Filtering gene_df with gene_map## Adding input_gene col to gene_df.## Adding ortholog_gene col to gene_df.##
## =========== REPORT SUMMARY ===========## Total genes dropped after convert_orthologs :
## 4,725 / 21,207 (22%)## Total genes remaining after convert_orthologs :
## 16,482 / 21,207 (78%)## --##
## =========== REPORT SUMMARY ===========## 16,482 / 21,207 (77.72%) target_species genes remain after ortholog conversion.## 16,482 / 19,129 (86.16%) reference_species genes remain after ortholog conversion.## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## --##
## =========== REPORT SUMMARY ===========## 19,129 / 19,129 (100%) target_species genes remain after ortholog conversion.## 19,129 / 19,129 (100%) reference_species genes remain after ortholog conversion.## 16,482 intersect background genes used.## Standardising CellTypeDataset## Checking gene list inputs.## Running without gene size control.## 22 hit gene(s) remain after filtering.## Computing gene scores.## Using previously sampled genes.## Computing gene counts.## Testing for enrichment in 7 cell types...## Sorting results by p-value.## Computing BH-corrected q-values.## 0 significant cell type enrichment results @ q<0.05 :
full_res2 = data.frame(full_results$results,
list="Alzheimers")
rando_res2 = data.frame(second_results$results,
list="Random")
merged_results = rbind(full_res2, rando_res2)Plot results
Here we apply multiple-testing correction (BH = Benjamini-Hochberg) to guard against positive results due to chance.
try({
plot_list <- EWCE::ewce_plot(total_res = merged_results,
mtc_method = "BH")
print(plot_list$plain)
})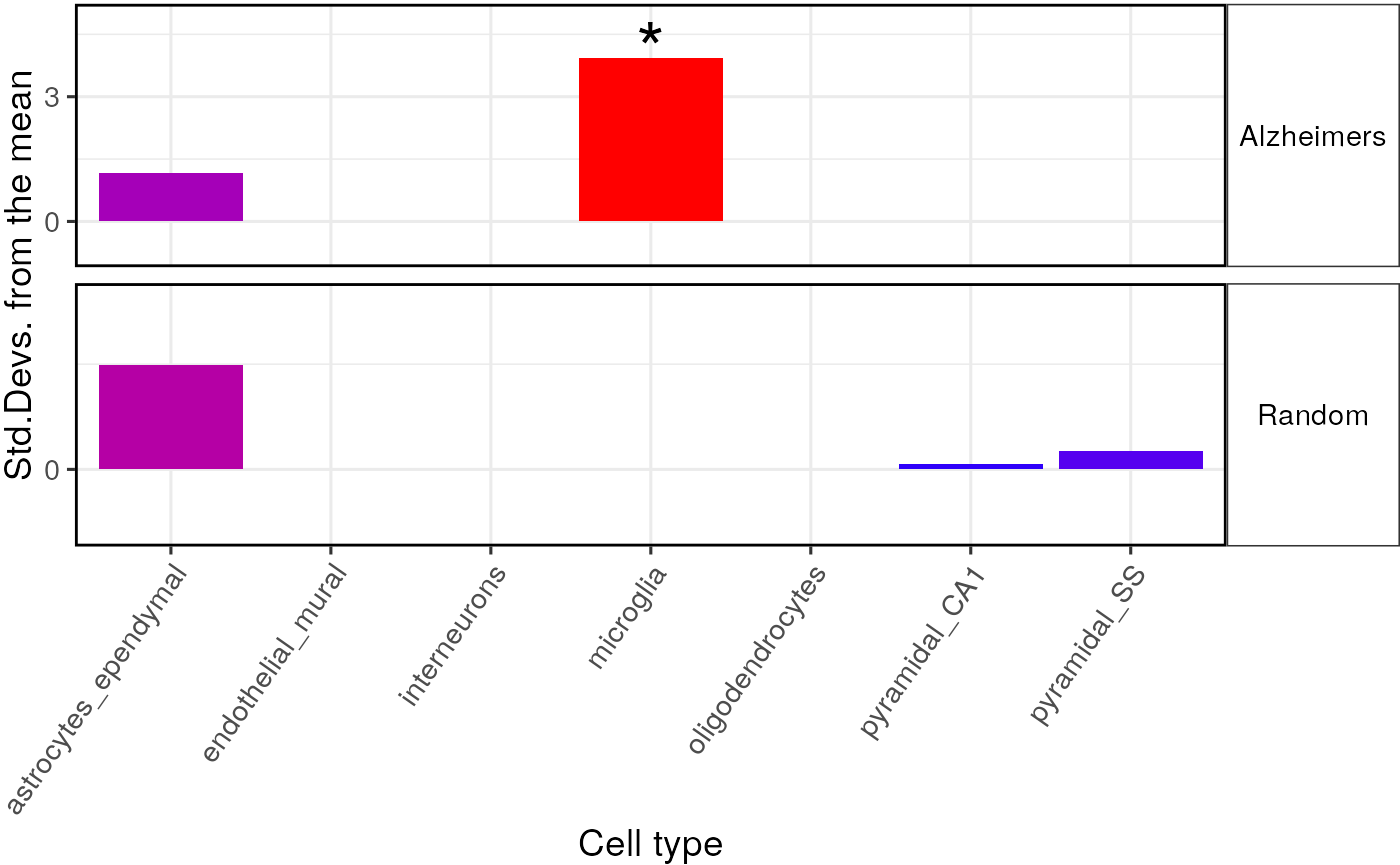
As expected, the second randomly generated gene list shows no significant enrichment results.
Create a CellTypeDataset
Introduction
EWCE was originally designed to work with the
single-cell cortical transcriptome data from the Linnarsson Lab1 (available here).
Using this package it is possible to read in any single-cell transcriptome data, provided that you have a cell by gene expression matrix (with each cell as a separate column) and a separate annotation dataframe, with a row for each cell.
The EWCE process involves testing for whether the genes
in a target list have higher levels of expression in a given cell type
than can reasonably be expected by chance. The probability distribution
for this is estimated by randomly generating gene lists of equal length
from a set of background genes.
EWCE can be applied to any gene list. In the original
paper we reported its application to genetic and transcriptomic
datasets2..
Note that throughout this vignette we use the terms ‘cell type’ and ‘cell subtype’ to refer to two levels of annotation of what a cell type is. This is described in further detail in our paper2, but relates to the two levels of annotation provided in the Linnarsson dataset1. In this dataset a cell is described as having a cell type (i.e. ‘Interneuron’) and subcell type (i.e. ‘Int11’ a.k.a Interneuron type 11).
Here we provide an example of converting a scRNA-seq dataset (Zeisel 2015) into a CellTypeDataset (CTD) so it can used with EWCE.
Loading datasets
The first step for all analyses is to load the single-cell transcriptome (SCT) data. For the purposes of this example we will use the dataset described in: > Cell types in the mouse cortex and hippocampus revealed by single-cell RNA-seq, Science, 2015
This is stored and can be loaded as follows from
ewceData package.
EWCE can generate CTD from two different data input types:
1. A gene x cell expression matrix (can be dense matrix, sparse matrix,
data.frame, or DelayedArray).
2. A SingleCellExperiment (SCE) or
SummarizedExperiment object.
To check the data, we can quickly plot the distribution of expression of a given gene across all the cell types.
# example datasets held in ewceData package
#if running offline pass localhub = TRUE
cortex_mrna <- ewceData::cortex_mrna()## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache
gene <- "Necab1"
cellExpDist <- data.frame(Expression=cortex_mrna$exp[gene,],
Celltype=cortex_mrna$annot[
colnames(cortex_mrna$exp),]$level1class)
try({
ggplot(cellExpDist) +
geom_boxplot(aes(x=Celltype, y=Expression), outlier.alpha = .5) +
theme_bw() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
})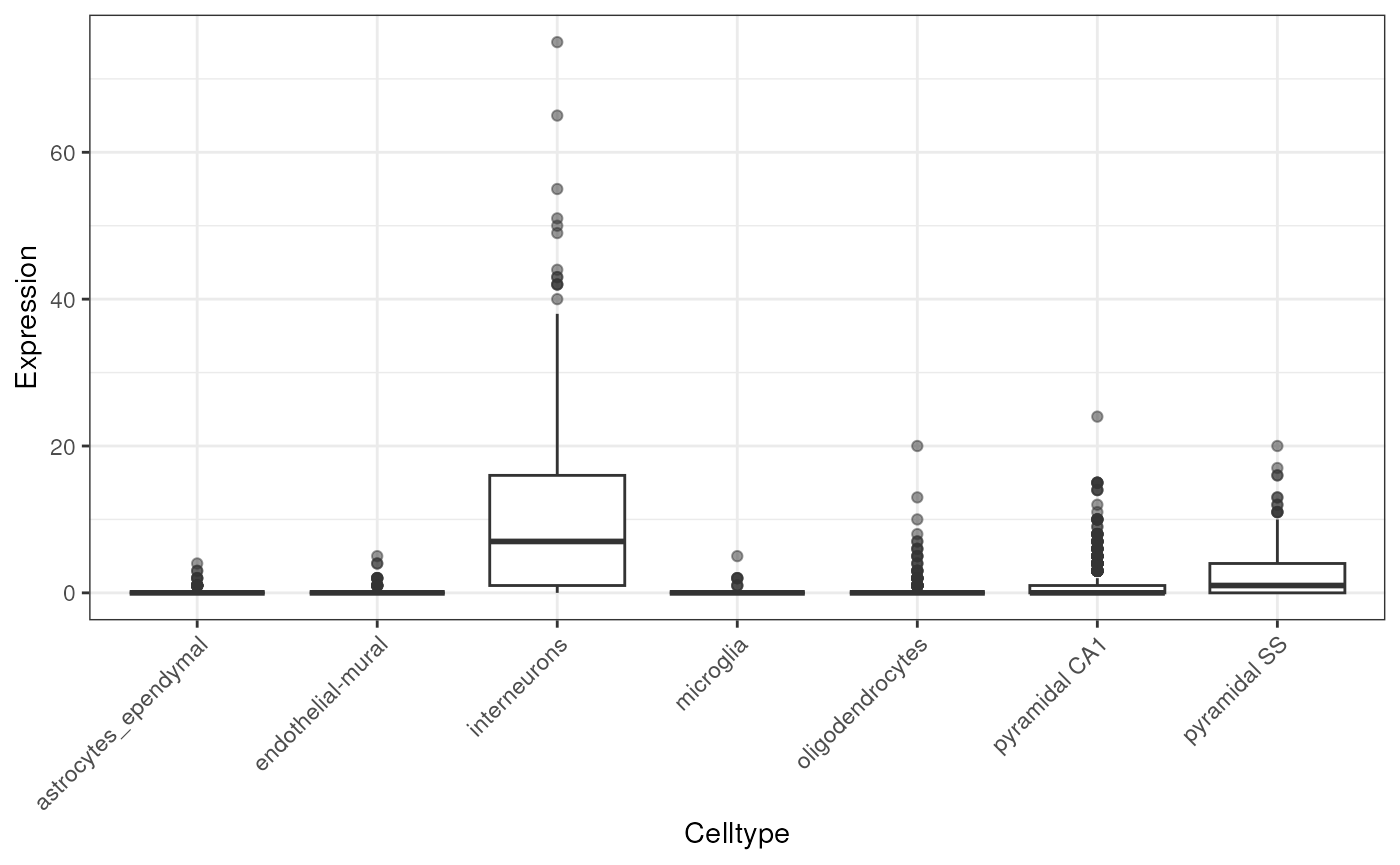
To note for the analysis of the cortex_mrna dataset, I
will proved the alternative for an SCE object under each segment of code
if there is any difference.
Convert single-cell formats
If you would like to try running the functions on an SCE object
instead, we can convert cortex_mrna with the package scKirby.
scKirby automatically infers the input file type and
converts it to SCE format by default.
if (!"SingleCellExperiment" %in% rownames(installed.packages())){BiocManager::install("SingleCellExperiment")}
library(SingleCellExperiment)
if (!"scKirby" %in% rownames(installed.packages())){remotes::install_github("bschilder/scKirby")}
library(scKirby)
# Make SCE object
cortex_mrna <- ewceData::cortex_mrna()
cortex_mrna_sce <- scKirby::ingest_data(cortex_mrna, save_output = FALSE)
# Now to plot the SCE dataset:
gene="Necab1"
cellExpDist_sce = data.frame(e=assays(cortex_mrna_sce)[[1]][gene,],
l1=colData(cortex_mrna_sce)[
colnames(assays(cortex_mrna_sce)[[1]]),
]$level1class)
ggplot(cellExpDist_sce) + geom_boxplot(aes(x=l1,y=e)) + xlab("Cell type") +
ylab("Unique Molecule Count") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) Correct gene symbols
It is very common for publicly available transcriptome datasets to use incorrect gene symbols (often some gene names will have been mangled by opening in Excel).
A function is provided to correct these where out of date aliases
were used and give a warning if appears possible that excel has mangled
some of the gene names. This function can be used with a downloaded
reference file like the MRK_List2
file from MGI which lists known synonyms for MGI gene symbols. If no
file path is passed, there is a loaded reference dataset of the
MRK_List2 which will be used: ewceData::mgi_synonym_data().
We recommend running this function on all input datasets.
#if running offline pass localhub = TRUE
cortex_mrna$exp = fix_bad_mgi_symbols(cortex_mrna$exp)Note - You can run
fix_bad_mgi_symbols() offline by passing
localhub = TRUE. This will work off a previously cached
version of the reference dataset from ExperimentHub.
For the SCE version, pass the whole SCE object:
#Note that data in SCE object must be in 'counts' assay
#The fix_bad_hgnc_symbols function can similarly take an SCE object as an input
cortex_mrna_sce = fix_bad_mgi_symbols(cortex_mrna_sce)Note - You can run
ewce_expression_data() offline by passing
localhub = TRUE. This will work off a previously cached
version of the reference dataset from ExperimentHub.
Drop genes
The vignette takes a while to go through if you use all genes. So let’s restrict to 1000 random genes.
nKeep <- 1000
must_keep <- c("Apoe","Gfap","Gapdh")
keep_genes <- c(must_keep,sample(rownames(cortex_mrna$exp),997))
cortex_mrna$exp <- cortex_mrna$exp[keep_genes,]
dim(cortex_mrna$exp)## [1] 1000 3005Normalization [Optional]
A different number of reads is found across each cell. We suggest
using scTransform
to normalise for differences due to cell size, then linearly scale. Note
that this might be slow.
cortex_mrna$exp_scT_normed <- EWCE::sct_normalize(cortex_mrna$exp) SingleCellExperiment
#### SCE ####
SummarizedExperiment::assays(cortex_mrna_sce)$normcounts <- EWCE::sct_normalize(SummarizedExperiment::assays(cortex_mrna_sce)$counts)Note that this is optional (and was not used in the original EWCE
publication) so by all means ignore this scTransform
step.
Calculate specificity matrices
Next,drop_uninformative_genes drops uninformative genes
in order to reduce compute time and noise in subsequent steps. It
achieves this through several steps, each of which are optional: 1.
Drop non-1:1 orthologs: Removes genes that don’t have
1:1 orthologs with the output_species (“human” by default). 2.
Drop non-varying genes: Removes genes that don’t vary
across cells based on variance deciles. 3. Drop
non-differentially expressed genes (DEGs): Removes genes that
are not significantly differentially expressed across cell-types.
Multiple DEG methods are currently available (see
?drop_uninformative_genes for up-to-date info).
Parallelisation
You can now speed up the DGE process by parallelising across multiple
cores with the parameter no_cores (=1 by
default).
# Generate cell type data for just the cortex/hippocampus data
exp_CortexOnly_DROPPED <- EWCE::drop_uninformative_genes(
exp = cortex_mrna$exp,
input_species = "mouse",
output_species = "human",
level2annot = cortex_mrna$annot$level2class) ## Warning: sctSpecies_origin not provided. Setting to 'mouse' by default.## 1 core(s) assigned as workers (3 reserved).## Converting to sparse matrix.## Checking for non-expressed genes.## Checking for cells with no expressed genes.## DGE:: Limma...## 229 / 1,000 genes dropped @ DGE adj_pval_thresh < 1e-05## Time difference of 0.2005835 secsGenerate CellTypeDataset
Now we generate the CellTypeDataset with the
By default the function returns the path where the resulting file was
saved. If you want to return the CTD itself as well, set
return_ctd=TRUE and it will be returned in a list (along
with the save path).
Parallelisation
You can now speed up generate_celltype_data by
parallelising across multiple cores with the parameter
no_cores (=1 by default).
annotLevels <- list(level1class=cortex_mrna$annot$level1class,
level2class=cortex_mrna$annot$level2class)
fNames_CortexOnly <- EWCE::generate_celltype_data(
exp = exp_CortexOnly_DROPPED,
annotLevels = annotLevels,
groupName = "kiCortexOnly") ## 1 core(s) assigned as workers (3 reserved).## Converting to sparse matrix.## + Calculating normalized mean expression.## Converting to sparse matrix.
## Converting to sparse matrix.## + Calculating normalized specificity.## Converting to sparse matrix.
## Converting to sparse matrix.
## Converting to sparse matrix.
## Converting to sparse matrix.## Loading required namespace: ggdendro## + Saving results ==> /tmp/RtmpJpNYvv/ctd_kiCortexOnly.rda
ctd_CortexOnly <- EWCE::load_rdata(fNames_CortexOnly)SingleCellExperiment
#### SCE ####
# Generate cell type data for just the cortex/hippocampus data
exp_CortexOnly_DROPPED <- drop_uninformative_genes(exp=cortex_mrna_sce,
drop_nonhuman_genes = T,
input_species = "mouse",
level2annot=cortex_mrna_sce$level2class)
annotLevels = list(level1class=cortex_mrna_sce$level1class,
level2class=cortex_mrna_sce$level2class)
fNames_CortexOnly <- generate_celltype_data(exp=exp_CortexOnly_DROPPED,
annotLevels=annotLevels,
groupName="kiCortexOnly",
savePath=tempdir()) To note on the SCE approach, these are the only differences for
handling the analysis of an SCE object. All downstream analysis on
cortex_mrna would be the same. The same approach can be
used for other datasets in the vignette if converted such as
hypothalamus_mrna or your own SCE object.
Merge two single-cell datasets
Often it is useful to merge two single-cell datasets. For instance,
there are separate files for the cortex and hypothalamus datasets
generated by the Karolinska institute. A subset of the resulting merged
dataset is loaded using ctd() but it is worth understanding
the approach (outlined below) if you want to repeat this for other
single-cell datasets.
The dataset is available from the GEO
but is also available in the ewceData package:
hypothalamus_mrna(). See the ewceData for
details of how this file was preprocessed after first being downloaded
from GEO, unzipped and read into R.
We can now merge the hypothalamus dataset with the cortex dataset and then calculate specificity:
Load hypothalamus dataset
#if running offline pass localhub = TRUE
hypothalamus_mrna <- ewceData::hypothalamus_mrna()## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cacheFix bad MGI symbols
#if running offline pass localhub = TRUE
hypothalamus_mrna$exp <- EWCE::fix_bad_mgi_symbols(exp = hypothalamus_mrna$exp)## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache## 1808 rows do not have proper MGI symbols## Rims1_loc1, Rims1_loc2, Fam178b_loc2, Fam178b_loc1, 2900092D14Rik, 4930487H11Rik, Spag16_loc1, Spag16_loc2, Pnkd_loc2, Pnkd_loc1, Ccdc108, 1700019O17Rik, Myeov2, Ren2, Gpr52, 1700015E13Rik, Olfr426, Hmga2-ps1, B020014A21Rik, Gm5512_loc1## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache## 0 poorly annotated genes are replicates of existing genes. These are:## ## Converting to sparse matrix.## 0 rows should have been corrected by checking synonyms.## 1808 rows STILL do not have proper MGI symbols.
cortex_mrna$exp <- EWCE::fix_bad_mgi_symbols(exp = cortex_mrna$exp)## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache## 68 rows do not have proper MGI symbols## 4930542D17Rik, A230070E04Rik, 4922505E12Rik, Agpat6, A730085A09Rik, 3110007F17Rik, AA387883, Azi1, Gm11237_loc2, Gm10778_loc1, Gm21950, LOC106740, Gm6194, Stxbp3a, Gm5820, Siglec5, A430092G05Rik, I730030J21Rik, Mir684-1_loc1, Gm10007## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache## 0 poorly annotated genes are replicates of existing genes. These are:## ## Converting to sparse matrix.## 31 rows should have been corrected by checking synonyms.## 37 rows STILL do not have proper MGI symbols.Merge CTD
Merge the CTDs - again this can be run with SCE or other ranged SE objects as input.
merged_KI <- EWCE::merge_two_expfiles(exp1 = hypothalamus_mrna$exp,
exp2 = cortex_mrna$exp,
annot1 = hypothalamus_mrna$annot,
annot2 = cortex_mrna$annot,
name1 = "Hypothalamus (KI)",
name2 = "Cortex/Hippo (KI)")## 23,317 non-overlapping gene(s) removed from exp1.## 0 non-overlapping gene(s) removed from exp2.## 1,000 intersecting genes remain.## Converting to data.frame
## Converting to data.frame## Converting to sparse matrix.Drop uninformative genes
Drop genes which don’t vary significantly between cell types.
exp_merged_DROPPED <- EWCE::drop_uninformative_genes(
exp = merged_KI$exp,
drop_nonhuman_genes = TRUE,
input_species = "mouse",
level2annot = merged_KI$annot$level2class)## Warning: sctSpecies_origin not provided. Setting to 'mouse' by default.## 1 core(s) assigned as workers (3 reserved).## Converting to sparse matrix.## Checking for non-expressed genes.## Checking for cells with no expressed genes.## DGE:: Limma...## 1 / 1,000 genes dropped @ DGE adj_pval_thresh < 1e-05## Time difference of 0.4345205 secsGenerate CellTypeDataset
annotLevels = list(level1class=merged_KI$annot$level1class,
level2class=merged_KI$annot$level2class)
# Update file path to where you want the cell type data files to save on disk
fNames_MergedKI <- EWCE::generate_celltype_data(exp = exp_merged_DROPPED,
annotLevels = annotLevels,
groupName = "MergedKI",
savePath = tempdir()) ## 1 core(s) assigned as workers (3 reserved).## Converting to sparse matrix.## + Calculating normalized mean expression.## Converting to sparse matrix.
## Converting to sparse matrix.## + Calculating normalized specificity.## Converting to sparse matrix.
## Converting to sparse matrix.
## Converting to sparse matrix.
## Converting to sparse matrix.## + Saving results ==> /tmp/RtmpJpNYvv/ctd_MergedKI.rda
ctd_MergedKI <- EWCE::load_rdata(fNames_MergedKI) Understanding specificity matrices
While not required for further analyses it helps to understand what the outputs of this function are.
Note firstly, that it is a list such that ctd[[1]]
contains data relating to level 1 annotations and ctd[[2]]
relates to level 2 annotations.
Using the ggplot2 package to visualise the data, let us
examine the expression of a few genes. If you have not already done so
you will need to first install the ggplot2 package with
install.packages("ggplot2").
For this example we use a subset of the genes from the merged dataset
generated above, which is accessed using ewceData::ctd().
We recommend that you use the code above to regenerate this though and
drop the first command from the below section.
## You can also import the pre-merged cortex and hypothalamus dataset
# generated by Karolinska institute. `ewceData::ctd()` is the same file as
# ctd_MergedKI above.
#if running offline pass localhub = TRUE
ctd <- ewceData::ctd()
ctd <- ctd_MergedKI
try({
plt <- EWCE::plot_ctd(ctd = ctd,
level = 1,
genes = c("Apoe","Gfap","Gapdh"),
metric = "mean_exp")
})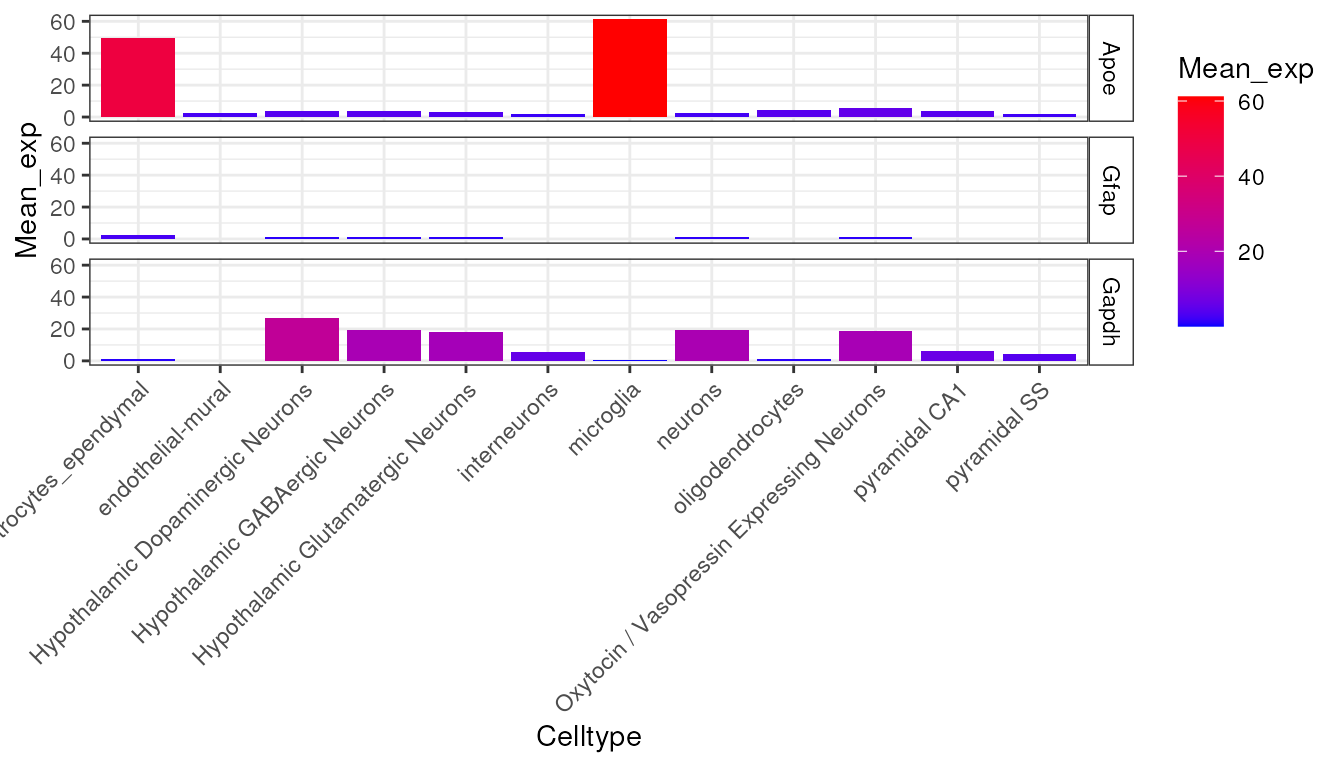
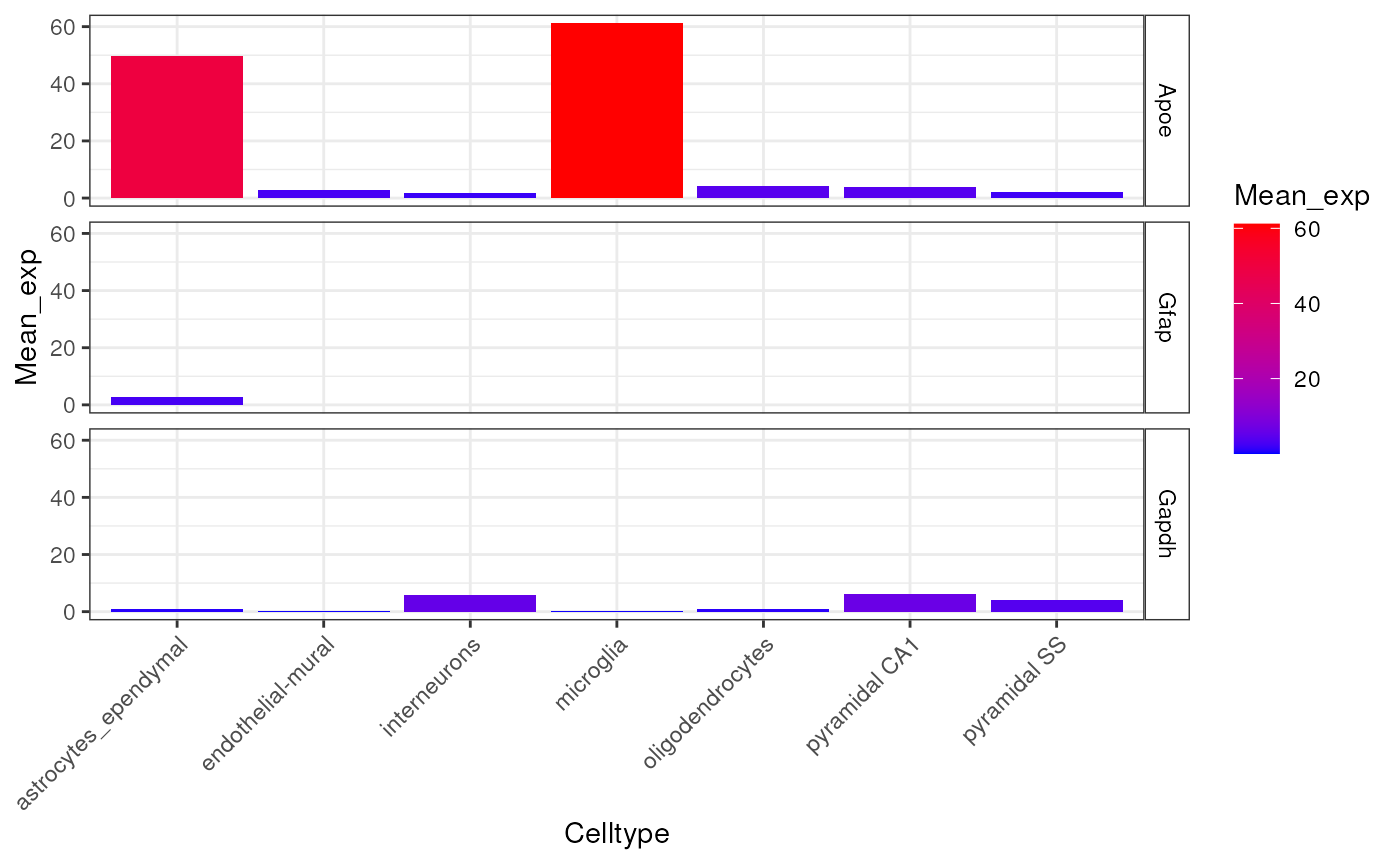
This graph shows the average expression of three genes: Apoe,
Gfap and Gapdh. While there are substantial differences in
which cell types express these genes, the dominant effect seen here is
the overall expression level of the data. For the purposes of this
analysis though, we are not interested in overall expression level and
only wish to know about the proportion of a genes expression which is
found in a particular cell type. We can study this instead using the
following code which examines the data frame
ctd[[1]]$specificity:
try({
plt <- EWCE::plot_ctd(ctd = ctd,
level = 1,
genes = c("Apoe","Gfap","Gapdh"),
metric = "specificity")
})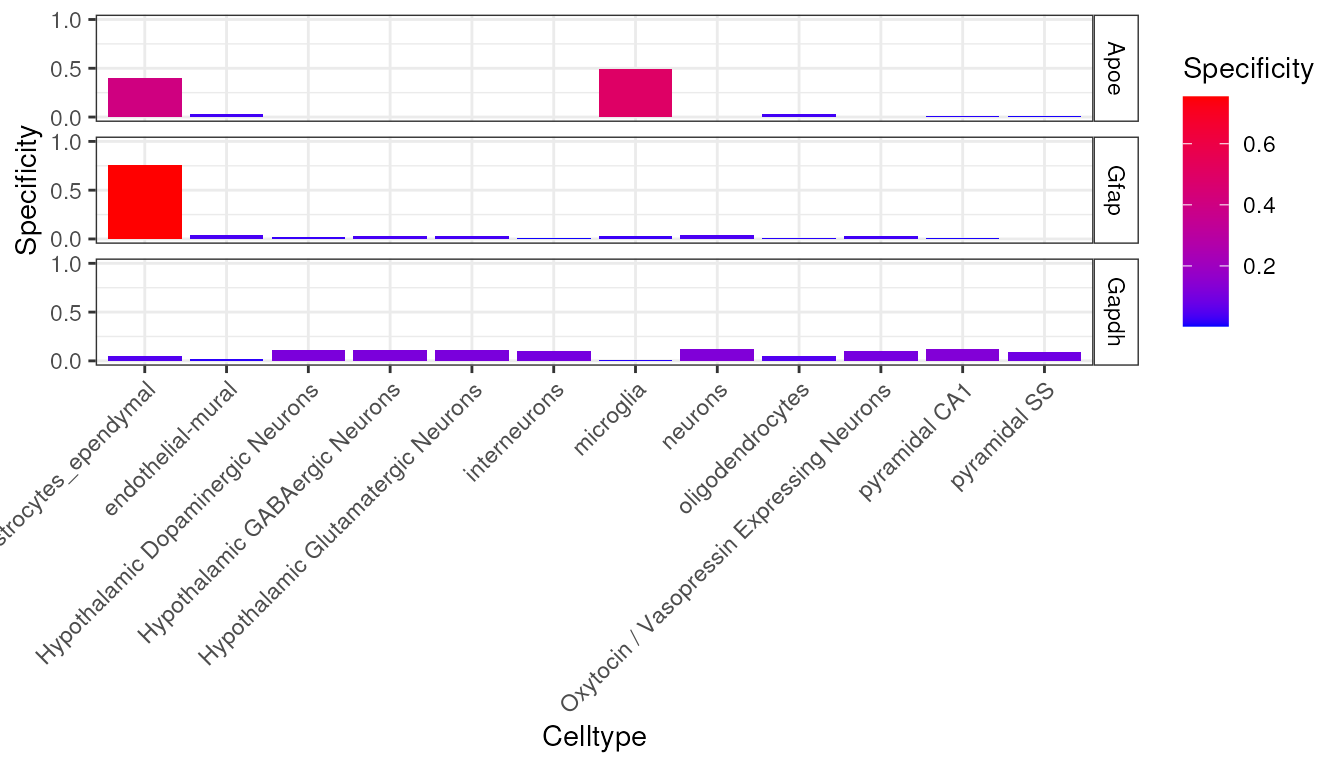
We can now see in this graph that Gfap is the most specific to a cell type (Type 1 Astrocytes) of any of those three genes, with over 60% of its expression found in that cell type.
It can also be seen that the majority of expression of Gapdh is in
neurons but because their are a greater number of neuronal subtypes, the
total expression proportion appears lower. We can examine expression
across level 2 cell type level annotations by looking at
ctd[[2]]$specificity:
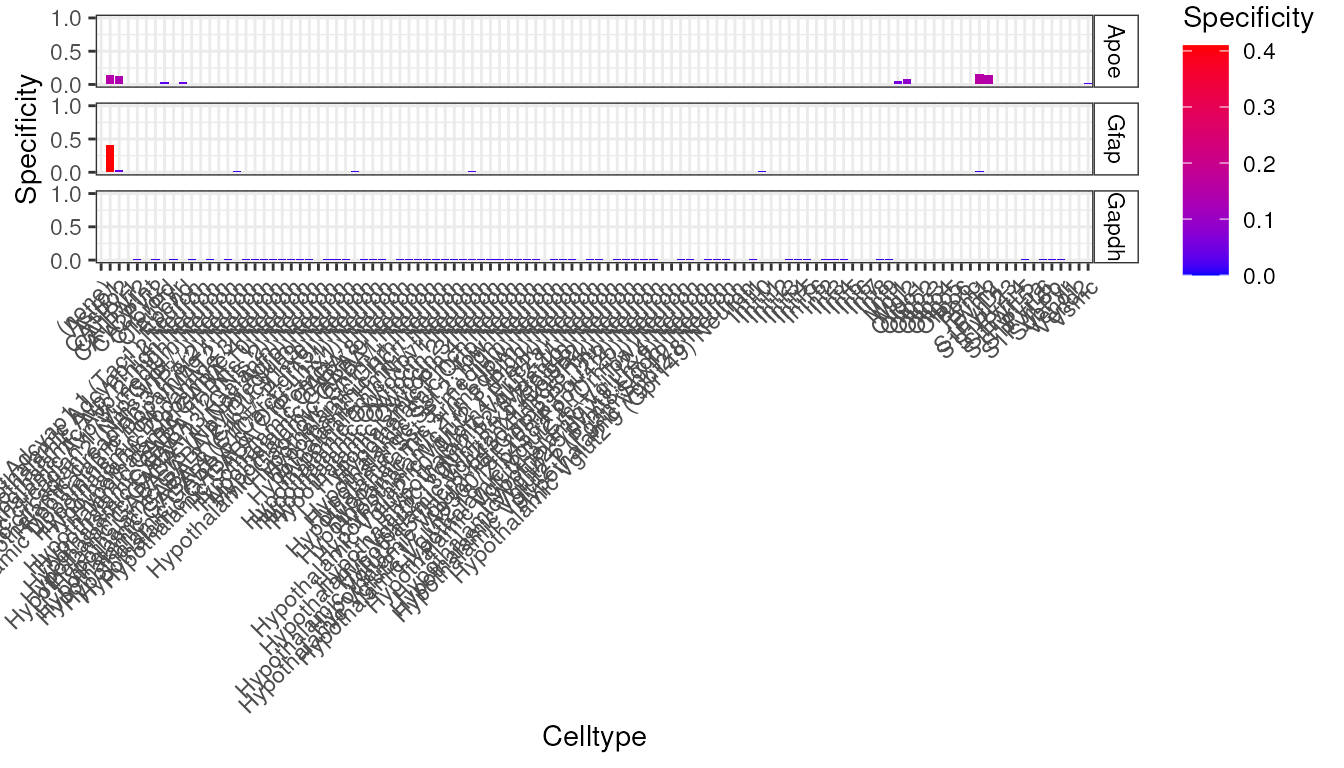
try({
plt <- EWCE::plot_ctd(ctd = ctd,
level = 2,
genes = c("Apoe","Gfap","Gapdh"),
metric = "specificity")
})
Run conditional cell-type enrichment tests
Prepare data
#if running offline pass localhub = TRUE
ctd <- ewceData::ctd()## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache
hits <- ewceData::example_genelist()## see ?ewceData and browseVignettes('ewceData') for documentation
## loading from cache
## NOTE: rep=100 for demo purposes only.
## Use >=10,000 for publication-quality results.
reps <- 100
annotLevel <- 1Controlling for expression in another cell type
In a followup paper we found that an enrichment detected for Schizophrenia in Somatosensory Pyramidal neurons could be explained by accounting for expression in Hippocampal CA1 pyramidal neurons. These results are described here:
Those results were generated using an alternative enrichment method designed for use with GWAS Summary Statistics rather than gene sets. The same sort of approach can be extended to EWCE as well, and we have implemented it within this package. When testing for enrichment the other gene sets that are sampled are selected to have equivalent specificity in the controlled cell type.
We demonstrate it’s use below to test whether the enrichment in astrocytes is still present after controlling for the enrichment within microglia.
Parallelisation
You can now speed up the bootstrapping process by parallelising
across multiple cores with the parameter no_cores
(=1 by default).
#if running offline pass localhub = TRUE
unconditional_results <- EWCE::bootstrap_enrichment_test(
sct_data = ctd,
hits = hits,
sctSpecies = "mouse",
genelistSpecies = "human",
reps = reps,
annotLevel = annotLevel)## 1 core(s) assigned as workers (3 reserved).## Generating gene background for mouse x human ==> human## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Using cached file: /github/home/.cache/R/orthogene/all_genes-10090-homologene.csv.gz## Returning all 21,207 genes from mouse.## --
## --## Preparing gene_df.## data.table format detected.## Extracting genes from Gene.Symbol.## 21,207 genes extracted.## Converting mouse ==> human orthologs using: homologene## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Checking for genes without orthologs in human.## Extracting genes from input_gene.## 17,355 genes extracted.## Extracting genes from ortholog_gene.## 17,355 genes extracted.## Checking for genes without 1:1 orthologs.## Dropping 131 genes that have multiple input_gene per ortholog_gene (many:1).## Dropping 498 genes that have multiple ortholog_gene per input_gene (1:many).## Filtering gene_df with gene_map## Adding input_gene col to gene_df.## Adding ortholog_gene col to gene_df.##
## =========== REPORT SUMMARY ===========## Total genes dropped after convert_orthologs :
## 4,725 / 21,207 (22%)## Total genes remaining after convert_orthologs :
## 16,482 / 21,207 (78%)## --##
## =========== REPORT SUMMARY ===========## 16,482 / 21,207 (77.72%) target_species genes remain after ortholog conversion.## 16,482 / 19,129 (86.16%) reference_species genes remain after ortholog conversion.## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## --##
## =========== REPORT SUMMARY ===========## 19,129 / 19,129 (100%) target_species genes remain after ortholog conversion.## 19,129 / 19,129 (100%) reference_species genes remain after ortholog conversion.## 16,482 intersect background genes used.## Standardising CellTypeDataset## Checking gene list inputs.## Running without gene size control.## 17 hit gene(s) remain after filtering.## Computing gene scores.## Using previously sampled genes.## Computing gene counts.## Testing for enrichment in 7 cell types...## Sorting results by p-value.## Computing BH-corrected q-values.## 1 significant cell type enrichment results @ q<0.05 :## CellType annotLevel p fold_change sd_from_mean q
## 1 microglia 1 0 2.099788 4.692166 0
conditional_results_micro <- EWCE:: bootstrap_enrichment_test(
sct_data = ctd,
hits = hits,
sctSpecies = "mouse",
genelistSpecies = "human",
reps = reps,
annotLevel = annotLevel,
controlledCT = "microglia")## 1 core(s) assigned as workers (3 reserved).## Generating gene background for mouse x human ==> human## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Using cached file: /github/home/.cache/R/orthogene/all_genes-10090-homologene.csv.gz## Returning all 21,207 genes from mouse.## --
## --## Preparing gene_df.## data.table format detected.## Extracting genes from Gene.Symbol.## 21,207 genes extracted.## Converting mouse ==> human orthologs using: homologene## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Checking for genes without orthologs in human.## Extracting genes from input_gene.## 17,355 genes extracted.## Extracting genes from ortholog_gene.## 17,355 genes extracted.## Checking for genes without 1:1 orthologs.## Dropping 131 genes that have multiple input_gene per ortholog_gene (many:1).## Dropping 498 genes that have multiple ortholog_gene per input_gene (1:many).## Filtering gene_df with gene_map## Adding input_gene col to gene_df.## Adding ortholog_gene col to gene_df.##
## =========== REPORT SUMMARY ===========## Total genes dropped after convert_orthologs :
## 4,725 / 21,207 (22%)## Total genes remaining after convert_orthologs :
## 16,482 / 21,207 (78%)## --##
## =========== REPORT SUMMARY ===========## 16,482 / 21,207 (77.72%) target_species genes remain after ortholog conversion.## 16,482 / 19,129 (86.16%) reference_species genes remain after ortholog conversion.## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## --##
## =========== REPORT SUMMARY ===========## 19,129 / 19,129 (100%) target_species genes remain after ortholog conversion.## 19,129 / 19,129 (100%) reference_species genes remain after ortholog conversion.## 16,482 intersect background genes used.## Standardising CellTypeDataset## Checking gene list inputs.## Running without gene size control.## 17 hit gene(s) remain after filtering.## Generating controlled bootstrap gene sets.## Computing gene scores.## Using previously sampled genes.## Computing gene counts.## Testing for enrichment in 7 cell types...## Sorting results by p-value.## Computing BH-corrected q-values.## 0 significant cell type enrichment results @ q<0.05 :
conditional_results_astro <- EWCE::bootstrap_enrichment_test(
sct_data = ctd,
hits = hits,
sctSpecies = "mouse",
genelistSpecies = "human",
reps = reps,
annotLevel = annotLevel,
controlledCT = "astrocytes_ependymal")## 1 core(s) assigned as workers (3 reserved).## Generating gene background for mouse x human ==> human## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Using cached file: /github/home/.cache/R/orthogene/all_genes-10090-homologene.csv.gz## Returning all 21,207 genes from mouse.## --
## --## Preparing gene_df.## data.table format detected.## Extracting genes from Gene.Symbol.## 21,207 genes extracted.## Converting mouse ==> human orthologs using: homologene## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Checking for genes without orthologs in human.## Extracting genes from input_gene.## 17,355 genes extracted.## Extracting genes from ortholog_gene.## 17,355 genes extracted.## Checking for genes without 1:1 orthologs.## Dropping 131 genes that have multiple input_gene per ortholog_gene (many:1).## Dropping 498 genes that have multiple ortholog_gene per input_gene (1:many).## Filtering gene_df with gene_map## Adding input_gene col to gene_df.## Adding ortholog_gene col to gene_df.##
## =========== REPORT SUMMARY ===========## Total genes dropped after convert_orthologs :
## 4,725 / 21,207 (22%)## Total genes remaining after convert_orthologs :
## 16,482 / 21,207 (78%)## --##
## =========== REPORT SUMMARY ===========## 16,482 / 21,207 (77.72%) target_species genes remain after ortholog conversion.## 16,482 / 19,129 (86.16%) reference_species genes remain after ortholog conversion.## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## --##
## =========== REPORT SUMMARY ===========## 19,129 / 19,129 (100%) target_species genes remain after ortholog conversion.## 19,129 / 19,129 (100%) reference_species genes remain after ortholog conversion.## 16,482 intersect background genes used.## Standardising CellTypeDataset## Checking gene list inputs.## Running without gene size control.## 17 hit gene(s) remain after filtering.## Generating controlled bootstrap gene sets.## Computing gene scores.## Using previously sampled genes.## Computing gene counts.## Testing for enrichment in 7 cell types...## Sorting results by p-value.## Computing BH-corrected q-values.## 0 significant cell type enrichment results @ q<0.05 :Merge and plot results
merged_results <- rbind(
data.frame(unconditional_results$results,
list="Unconditional Enrichment"),
data.frame(conditional_results_micro$results,
list="Conditional Enrichment (Microglia controlled)"),
data.frame(conditional_results_astro$results,
list="Conditional Enrichment (Astrocyte controlled)")
)
try({
plot_list <- EWCE::ewce_plot(total_res = merged_results,
mtc_method = "BH")
print(plot_list$plain)
})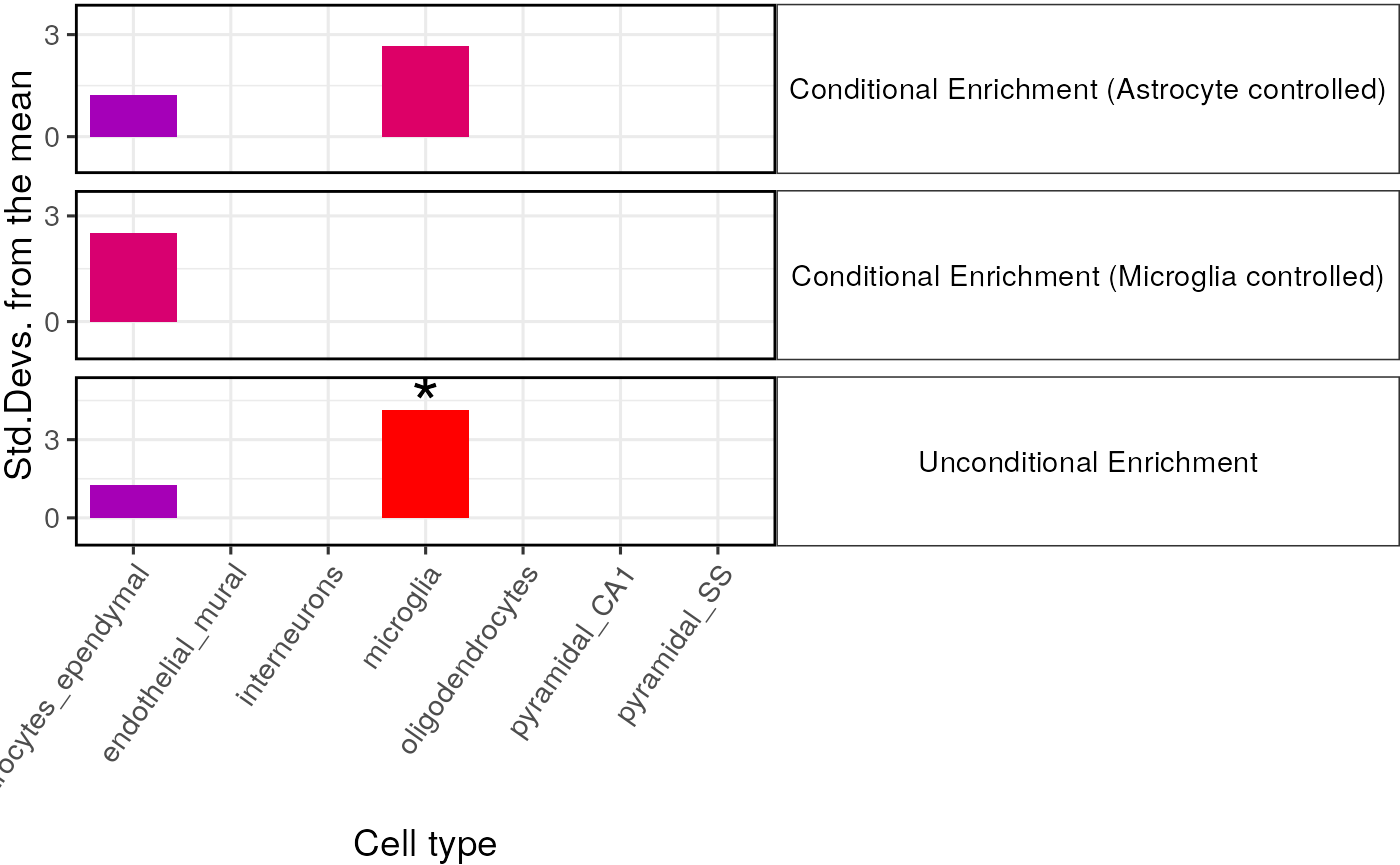
When controlling for astrocytes the enrichment in astrocytes is totally abolished as expected, and vica versa. The enrichment in microglia remains strongly significant however after controlling for astrocytes., suggesting that this enrichment is independent of that in astrocytes.
Gene set enrichment analysis controlling for cell type expression
Traditionally the standard analysis run on all gene sets was the GO enrichment analysis. Once you have established that a given gene list is enriched for a given cell type, it becomes questionable whether a GO enrichment is driven purely by the underlying cell type enrichment. For instance, it is well established that genes associated with schizophrenia are enriched for the human post-synaptic density genes, however, it has also been shown that schizophrenia is enriched for specificity in CA1 pyramidal neurons (which highly express hPSD genes). These two enrichments can be disassociated using the following analysis:
# set seed for bootstrap reproducibility
mouse_to_human_homologs <- ewceData::mouse_to_human_homologs()
m2h = unique(mouse_to_human_homologs[,c("HGNC.symbol","MGI.symbol")])
schiz_genes <- ewceData::schiz_genes()
id_genes <- ewceData::id_genes()
mouse.hits.schiz = unique(m2h[m2h$HGNC.symbol %in% schiz_genes,"MGI.symbol"])
mouse.hits.id = unique(m2h[m2h$HGNC.symbol %in% id_genes,"MGI.symbol"])
mouse.bg = unique(m2h$MGI.symbol)
hpsd_genes <- ewceData::hpsd_genes()
mouse.hpsd = unique(m2h[m2h$HGNC.symbol %in% hpsd_genes,"MGI.symbol"])
rbfox_genes <- ewceData::rbfox_genes()
res_hpsd_schiz = controlled_geneset_enrichment(disease_genes=mouse.hits.schiz,
functional_genes = mouse.hpsd,
bg_genes = mouse.bg,
sct_data = ctd,
annotLevel = 1,
reps=reps,
controlledCT="pyramidal CA1")
res_rbfox_schiz =
controlled_geneset_enrichment(disease_genes=mouse.hits.schiz,
functional_genes = rbfox_genes,
bg_genes = mouse.bg,
sct_data = ctd,
annotLevel = 1,
reps=reps,
controlledCT="pyramidal CA1")
print(res_hpsd_schiz)
print(res_rbfox_schiz)
res_hpsd_id =
controlled_geneset_enrichment(disease_genes=mouse.hits.id,
functional_genes = mouse.hpsd,
bg_genes = mouse.bg,
sct_data = ctd,
annotLevel = 1,
reps=reps,
controlledCT = "pyramidal SS")
res_rbfox_id = controlled_geneset_enrichment(disease_genes=mouse.hits.id,
functional_genes = rbfox_genes,
bg_genes = mouse.bg,
sct_data = ctd,
annotLevel = 1,
reps=reps,
controlledCT="pyramidal SS")
print(res_hpsd_id)
print(res_rbfox_id)The analysis also tests for enrichment of Rbfox binding genes in the schizophrenia susceptibility genes, as well as both hPSD and Rbfox genes in Intellectual Disability genes. All of the enrichments are confirmed as still being present after controlling for the associated cell type, apart from the enrichment of PSD genes in Schizophrenia which falls from borderline to non-significant.
Controlling for multiple cell types
controlledCTs = c("pyramidal CA1","pyramidal SS","interneurons")
res_hpsd_schiz =
controlled_geneset_enrichment(disease_genes=mouse.hits.schiz,
functional_genes = mouse.hpsd,
bg_genes = mouse.bg,
sct_data = ctd,
annotLevel = 1,
reps=reps,
controlledCT=controlledCTs)
res_rbfox_schiz =
controlled_geneset_enrichment(disease_genes=mouse.hits.schiz,
functional_genes = rbfox_genes,
bg_genes = mouse.bg, sct_data = ctd,
annotLevel = 1, reps=reps,
controlledCT=controlledCTs)
print(res_hpsd_schiz)
print(res_rbfox_schiz)
res_hpsd_id =
controlled_geneset_enrichment(disease_genes=mouse.hits.id,
functional_genes = mouse.hpsd,
bg_genes = mouse.bg,
sct_data = ctd,
annotLevel = 1,
reps=reps,
controlledCT=controlledCTs)
res_rbfox_id = controlled_geneset_enrichment(disease_genes=mouse.hits.id,
functional_genes = rbfox_genes,
bg_genes = mouse.bg,
sct_data = ctd,
annotLevel = 1,
reps=reps,
controlledCT=controlledCTs)
print(res_hpsd_id)
print(res_rbfox_id)Apply to transcriptomic data
Prepare data
#if running offline pass localhub = TRUE
ctd <- ewceData::ctd()## see ?ewceData and browseVignettes('ewceData') for documentation## loading from cache
tt_alzh <- ewceData::tt_alzh()## see ?ewceData and browseVignettes('ewceData') for documentation
## loading from cache
## NOTE: rep=100 for demo purposes only.
## Use >=10,000 for publication-quality results.
reps <- 100 Analysing single transcriptome study
For the prior analyses the gene lists were not associated with any numeric values or directionality. The methodology for extending this form of analysis to transcriptomic studies simply involves thresholding the most upregulated and downregulated genes.
To demonstrate this we have an example dataset tt_alzh.
This data frame was generated using limma from a set of
post-mortem tissue samples from Brodmann area 46 which were described in
a paper by the Haroutunian lab3.
The first step is to load the data, obtain the MGI ids, sort the rows
by t-statistic and then select the most up/down-regulated genes. The
package then has a function ewce_expression_data which
thresholds and selects the gene sets, and calls the EWCE function.
Below we show the function call using the default settings, but if desired different threshold values can be used, or alternative columns used to sort the table.
# ewce_expression_data calls bootstrap_enrichment_test so
tt_results <- EWCE::ewce_expression_data(sct_data = ctd,
tt = tt_alzh,
annotLevel = 1,
ttSpecies = "human",
sctSpecies = "mouse")## Warning: genelistSpecies not provided. Setting to 'human' by default.## Warning: sctSpecies_origin not provided. Setting to 'mouse' by default.
## Warning: sctSpecies_origin not provided. Setting to 'mouse' by default.## Preparing gene_df.## character format detected.## Converting to data.frame## Extracting genes from input_gene.## 15,259 genes extracted.## Converting mouse ==> human orthologs using: homologene## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Checking for genes without orthologs in human.## Extracting genes from input_gene.## 13,416 genes extracted.## Extracting genes from ortholog_gene.## 13,416 genes extracted.## Checking for genes without 1:1 orthologs.## Dropping 46 genes that have multiple input_gene per ortholog_gene (many:1).## Dropping 56 genes that have multiple ortholog_gene per input_gene (1:many).## Filtering gene_df with gene_map## Returning gene_map as dictionary##
## =========== REPORT SUMMARY ===========## Total genes dropped after convert_orthologs :
## 2,016 / 15,259 (13%)## Total genes remaining after convert_orthologs :
## 13,243 / 15,259 (87%)## Generating gene background for mouse x human ==> human## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Using cached file: /github/home/.cache/R/orthogene/all_genes-10090-homologene.csv.gz## Returning all 21,207 genes from mouse.## --
## --## Preparing gene_df.## data.table format detected.## Extracting genes from Gene.Symbol.## 21,207 genes extracted.## Converting mouse ==> human orthologs using: homologene## Retrieving all organisms available in homologene.## Mapping species name: mouse## Common name mapping found for mouse## 1 organism identified from search: 10090## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Checking for genes without orthologs in human.## Extracting genes from input_gene.## 17,355 genes extracted.## Extracting genes from ortholog_gene.## 17,355 genes extracted.## Checking for genes without 1:1 orthologs.## Dropping 131 genes that have multiple input_gene per ortholog_gene (many:1).## Dropping 498 genes that have multiple ortholog_gene per input_gene (1:many).## Filtering gene_df with gene_map## Adding input_gene col to gene_df.## Adding ortholog_gene col to gene_df.##
## =========== REPORT SUMMARY ===========## Total genes dropped after convert_orthologs :
## 4,725 / 21,207 (22%)## Total genes remaining after convert_orthologs :
## 16,482 / 21,207 (78%)## --##
## =========== REPORT SUMMARY ===========## 16,482 / 21,207 (77.72%) target_species genes remain after ortholog conversion.## 16,482 / 19,129 (86.16%) reference_species genes remain after ortholog conversion.## Gathering ortholog reports.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## --##
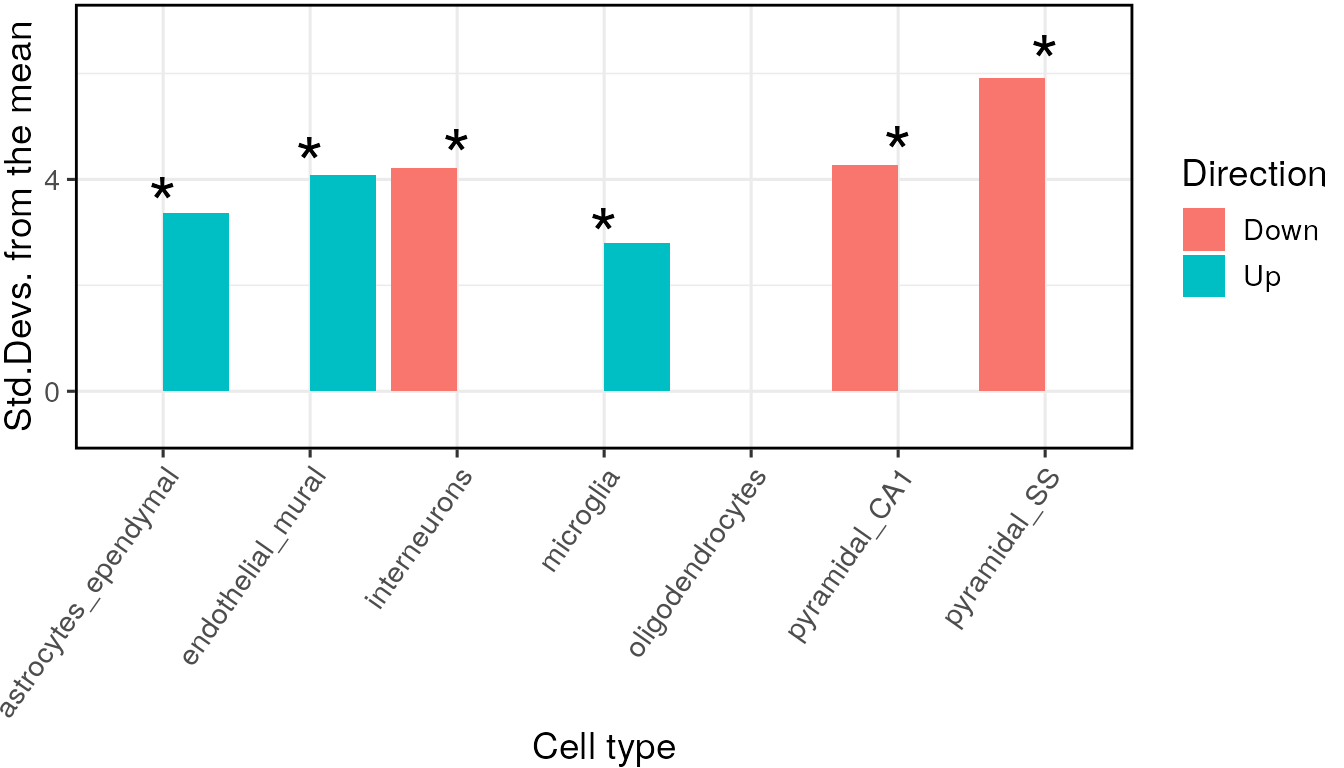
## =========== REPORT SUMMARY ===========## 19,129 / 19,129 (100%) target_species genes remain after ortholog conversion.## 19,129 / 19,129 (100%) reference_species genes remain after ortholog conversion.## 16,482 intersect background genes used.## Retrieving all genes using: homologene.## Retrieving all organisms available in homologene.## Mapping species name: human## Common name mapping found for human## 1 organism identified from search: 9606## Using cached file: /github/home/.cache/R/orthogene/all_genes-9606-homologene.csv.gz## Returning all 19,129 genes from human.## Returning 19,129 unique genes from entire human genome.## Using intersect between background gene lists: 16,482 genes.## Standardising sct_data.## Using 1st column of tt as gene column: HGNC.symbol## 1 core(s) assigned as workers (3 reserved).## Standardising CellTypeDataset## Checking gene list inputs.## Running without gene size control.## 224 hit gene(s) remain after filtering.## Computing gene scores.## Using previously sampled genes.## Computing gene counts.## Testing for enrichment in 7 cell types...## Sorting results by p-value.## Computing BH-corrected q-values.## 3 significant cell type enrichment results @ q<0.05 :## CellType annotLevel p fold_change sd_from_mean q
## 1 endothelial_mural 1 0.00 1.248901 4.266810 0.00000000
## 2 astrocytes_ependymal 1 0.00 1.207702 3.255269 0.00000000
## 3 microglia 1 0.01 1.211037 2.948742 0.02333333## 1 core(s) assigned as workers (3 reserved).## Standardising CellTypeDataset## Checking gene list inputs.## Running without gene size control.## 232 hit gene(s) remain after filtering.## Computing gene scores.## Using previously sampled genes.## Computing gene counts.## Testing for enrichment in 7 cell types...## Sorting results by p-value.## Computing BH-corrected q-values.## 3 significant cell type enrichment results @ q<0.05 :## CellType annotLevel p fold_change sd_from_mean q
## 1 pyramidal_SS 1 0 1.295520 6.054133 0
## 2 pyramidal_CA1 1 0 1.221332 4.429679 0
## 3 interneurons 1 0 1.212988 3.982445 0Note - You can run
ewce_expression_data() offline by passing
localhub = TRUE. This will work off a previously cached
version of the reference dataset from ExperimentHub.
Generating bootstrap plots for transcriptomes
A common request is to explain which differentially expressed genes are associated with a cell type…
full_result_path <- EWCE::generate_bootstrap_plots_for_transcriptome(
sct_data = ctd,
tt = tt_alzh,
annotLevel = 1,
full_results = tt_results,
listFileName = "examples",
reps = reps,
ttSpecies = "human",
sctSpecies = "mouse",
sig_only = FALSE)Merging multiple transcriptome studies
Where multiple transcriptomic studies have been performed with the same purpose, i.e. seeking differential expression in dlPFC of post-mortem schizophrenics, it is common to want to determine whether they exhibit any shared signal. EWCE can be used to merge the results of multiple studies.
To demonstrate this we use a two further Alzheimer’s transcriptome
datasets coming from Brodmann areas 36 and 44: these area stored in
tt_alzh_BA36 and tt_alzh_BA44. The first step
is to run EWCE on each of these individually and store the output into
one list.
Load data
#if running offline pass localhub = TRUE
tt_alzh_BA36 <- ewceData::tt_alzh_BA36()
tt_alzh_BA44 <- ewceData::tt_alzh_BA44() Run EWCE analysis
tt_results_36 <- EWCE::ewce_expression_data(sct_data = ctd,
tt = tt_alzh_BA36,
annotLevel = 1,
ttSpecies = "human",
sctSpecies = "mouse")
tt_results_44 <- EWCE::ewce_expression_data(sct_data = ctd,
tt = tt_alzh_BA44,
annotLevel = 1,
ttSpecies = "human",
sctSpecies = "mouse")
# Fill a list with the results
results <- EWCE::add_res_to_merging_list(tt_results)
results <- EWCE::add_res_to_merging_list(tt_results_36,results)
results <- EWCE::add_res_to_merging_list(tt_results_44,results)
# Perform the merged analysis
# For publication reps should be higher
merged_res <- EWCE::merged_ewce(results = results,
reps = 10)
print(merged_res)The results can then be plotted as normal using the
ewce_plot function.
The merged results from all three Alzheimer’s brain regions are found to be remarkably similar, as was reported in our paper.
Session Info
utils::sessionInfo()## R Under development (unstable) (2026-03-15 r89629)
## Platform: x86_64-pc-linux-gnu
## Running under: Ubuntu 24.04.4 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## time zone: UTC
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] ewceData_1.19.0 ExperimentHub_3.1.0 AnnotationHub_4.1.0
## [4] BiocFileCache_3.1.0 dbplyr_2.5.2 BiocGenerics_0.57.0
## [7] generics_0.1.4 ggplot2_4.0.2 EWCE_1.19.1
## [10] RNOmni_1.0.1.2 BiocStyle_2.39.0
##
## loaded via a namespace (and not attached):
## [1] RColorBrewer_1.1-3 ggdendro_0.2.0
## [3] jsonlite_2.0.0 magrittr_2.0.4
## [5] farver_2.1.2 rmarkdown_2.30
## [7] fs_1.6.7 ragg_1.5.1
## [9] vctrs_0.7.1 memoise_2.0.1
## [11] ggtree_4.1.1 rstatix_0.7.3
## [13] htmltools_0.5.9 S4Arrays_1.11.1
## [15] curl_7.0.0 broom_1.0.12
## [17] SparseArray_1.11.11 Formula_1.2-5
## [19] gridGraphics_0.5-1 sass_0.4.10
## [21] bslib_0.10.0 htmlwidgets_1.6.4
## [23] desc_1.4.3 plyr_1.8.9
## [25] HGNChelper_0.8.15 httr2_1.2.2
## [27] plotly_4.12.0 cachem_1.1.0
## [29] lifecycle_1.0.5 pkgconfig_2.0.3
## [31] Matrix_1.7-4 R6_2.6.1
## [33] fastmap_1.2.0 MatrixGenerics_1.23.0
## [35] digest_0.6.39 aplot_0.2.9
## [37] patchwork_1.3.2 AnnotationDbi_1.73.0
## [39] S4Vectors_0.49.0 textshaping_1.0.5
## [41] GenomicRanges_1.63.1 RSQLite_2.4.6
## [43] ggpubr_0.6.3 labeling_0.4.3
## [45] filelock_1.0.3 httr_1.4.8
## [47] abind_1.4-8 compiler_4.6.0
## [49] withr_3.0.2 bit64_4.6.0-1
## [51] fontquiver_0.2.1 S7_0.2.1
## [53] backports_1.5.0 BiocParallel_1.45.0
## [55] orthogene_1.17.2 carData_3.0-6
## [57] DBI_1.3.0 homologene_1.4.68.19.3.27
## [59] R.utils_2.13.0 ggsignif_0.6.4
## [61] MASS_7.3-65 rappdirs_0.3.4
## [63] DelayedArray_0.37.0 tools_4.6.0
## [65] splitstackshape_1.4.8 otel_0.2.0
## [67] ape_5.8-1 R.oo_1.27.1
## [69] glue_1.8.0 nlme_3.1-168
## [71] grid_4.6.0 reshape2_1.4.5
## [73] gtable_0.3.6 R.methodsS3_1.8.2
## [75] tidyr_1.3.2 data.table_1.18.2.1
## [77] car_3.1-5 XVector_0.51.0
## [79] stringr_1.6.0 BiocVersion_3.23.1
## [81] pillar_1.11.1 yulab.utils_0.2.4
## [83] babelgene_22.9 limma_3.67.0
## [85] dplyr_1.2.0 treeio_1.35.0
## [87] lattice_0.22-9 bit_4.6.0
## [89] tidyselect_1.2.1 fontLiberation_0.1.0
## [91] SingleCellExperiment_1.33.1 Biostrings_2.79.5
## [93] knitr_1.51 fontBitstreamVera_0.1.1
## [95] bookdown_0.46 IRanges_2.45.0
## [97] Seqinfo_1.1.0 SummarizedExperiment_1.41.1
## [99] stats4_4.6.0 xfun_0.56
## [101] Biobase_2.71.0 statmod_1.5.1
## [103] matrixStats_1.5.0 stringi_1.8.7
## [105] lazyeval_0.2.2 ggfun_0.2.0
## [107] yaml_2.3.12 codetools_0.2-20
## [109] evaluate_1.0.5 gdtools_0.5.0
## [111] tibble_3.3.1 BiocManager_1.30.27
## [113] ggplotify_0.1.3 cli_3.6.5
## [115] systemfonts_1.3.2 jquerylib_0.1.4
## [117] Rcpp_1.1.1 gprofiler2_0.2.4
## [119] png_0.1-9 parallel_4.6.0
## [121] pkgdown_2.2.0 blob_1.3.0
## [123] viridisLite_0.4.3 tidytree_0.4.7
## [125] ggiraph_0.9.6 scales_1.4.0
## [127] purrr_1.2.1 crayon_1.5.3
## [129] rlang_1.1.7 KEGGREST_1.51.1